前段时间,同事遇到Java的GC问题,现象表现为:gc时间越来越长(也包括young gc);触发一次full gc之后,会变得好点,但是这次full gc长的不能忍受。他们使用的jdk 8,应用内存8G,尝试调整了很多参数,用了ParNew算法,也试过G1算法,都没有太大好转。困扰很久之后找我帮忙看一下,所以也就有了这篇文章^_^
GC对于我们来说相对黑盒,尤其是young gc的问题,幸运的是这次解决非常快且没依赖Google。对我而言,主要是解决问题过程中的思路,值得记录下来。至于gc的根本原因,事后我找到了笨神的博客
先简单分析分析
从gc的现象来看,可以有一些简单的分析:
- 程序跑了很久之后,开始young gc变长、full gc变长
- 感觉是每次full gc完成之后,young gc性能会短暂变好
- full gc自身也很慢
- full gc之后,会回收很多内存,有一个断崖式地下降,感觉有大量内存并不是程序所需要的
- young gc问题应该和old区相关
结合这些分析,第一反应是:进行root扫描的时候有点慢。由于并不熟悉业务代码,所以很难说是不是由于业务代码写的不好导致。但不管怎么说,我还是打算先看看gc日志。
解决问题
拿到gc的日志之后,发现日志太多了,一行行看是不现实的,必须要有目的性才行。由于CMS的日志每个阶段都挺详细的,可以重点关注。我又回到开始的分析上去,既然感觉full gc之后,ParNew GC会变快,那么是不是每次都这样呢?我开始先过滤full gc触发的时间点,得到一个重要的信息:程序刚开始的时候,full gc前后ParNew GC没有太大时间上的区别,也就是说程序一开始是正常的。我继续往下翻,直到找到full gc成为分水岭————前后的gc时间显著不一样。
我在2个full gc周围进行对比,发现了一些异常:在CMS的Final Remark阶段,出现了一个scrub string table的项
- 有时候很短

- 有时候很长
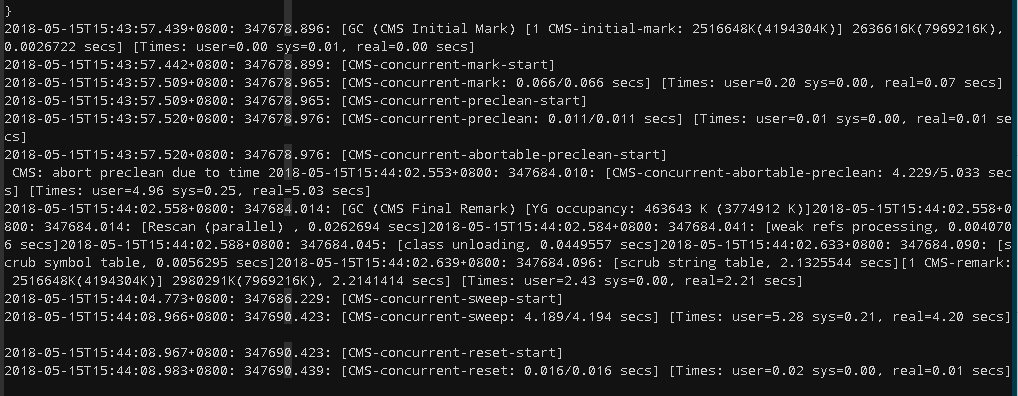
由于这个阶段是STW的,换句话说scrub string table的长短直接影响了gc暂停的时间。
看到String Table就很开心了,因为它和jdk的String.intern方法是有关系的,而intern方法在很多有关性能的博客里都有提到,是一个有争议的动作(有利有弊)。虽然不知道和gc有多大关系,但是对于我们解决问题,有了清晰的方向:优先找到谁在使用这个方法。因为是服务器程序,所以不可避免会使用Jackson序列化,序列化通常都是和String打交道的,所以我第一时间去看了Jackson的代码,果然默认Jackson默认是使用intern方法的。本着“在不懂原理的情况下,优先尝试的原则”,我们紧急发了一个版本,通过API关闭了Jackson的这项功能,然后在线上灰度测试。
结果很不错:不仅应用占用的内存变少了,而且gc变得非常的快速且稳定————问题顺利解决。
结尾
到这里,本文就结束了,至于后续分析产生的根本原因,这些都不是本文的重点。总结一下:这次的case并不算复杂,解决的时间也很短,但却具有代表性。我觉得解决问题就是:首先要尽量“从现象中分析出”大致的方向,“通过技术手段”找到怀疑的点,“快速尝试”(主要是我们掌握的知识有限,有时候碰碰运气效果会更好)来解决问题,最后再辅以“分析根因和总结”就好了。